
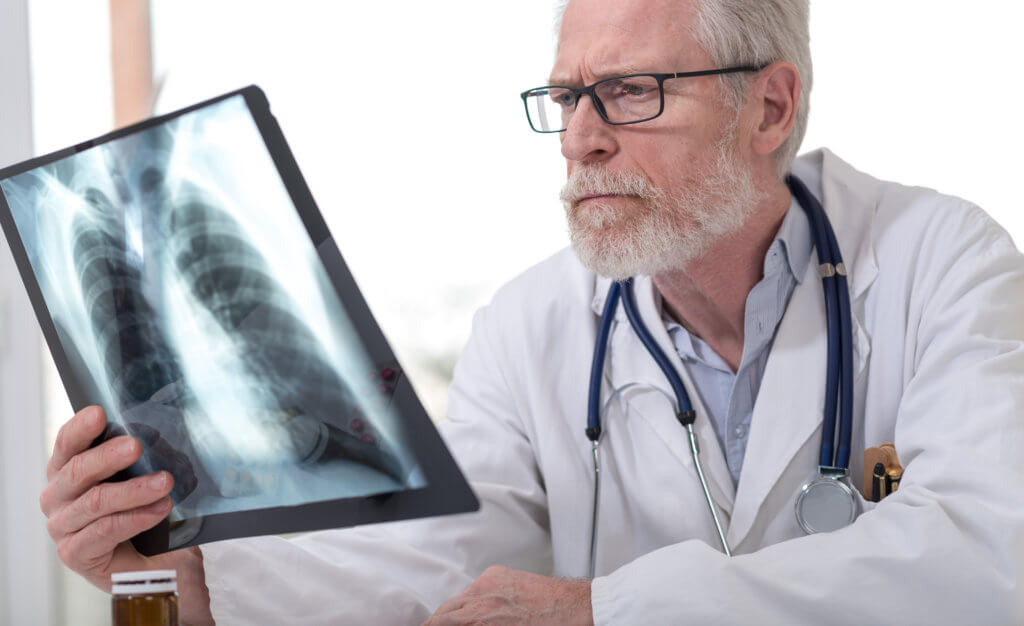
(Photo by Phonlamai Photo on Shutterstock)
OAK BROOK, Ill. — Can a machine do a better job of diagnosing patients after an X-ray or MRI? The latest version of ChatGPT, an artificial intelligence (AI) chatbot, is capable of passing a radiology board-style exam, researchers report. Study authors with the Radiological Society of North America (RSNA) believe this work highlights the potential of large language models while simultaneously revealing the limitations that hamper reliability.
ChatGPT uses a deep learning model to recognize patterns and relationships between words to generate surprisingly human-like responses based on the questions people pose. However, researchers say it’s very important to understand that while ChatGPT may do a great job of impersonating human dialogue, there is no source of truth in its training data, meaning the tool can generate responses that may be factually incorrect.
“The use of large language models like ChatGPT is exploding and only going to increase,” says lead study author Rajesh Bhayana, M.D., FRCPC, an abdominal radiologist and technology lead at University Medical Imaging Toronto, Toronto General Hospital in Toronto, Canada, in a media release. “Our research provides insight into ChatGPT’s performance in a radiology context, highlighting the incredible potential of large language models, along with the current limitations that make it unreliable.”
Human radiologists are medical doctors that specialize in diagnosing and treating injuries and diseases using medical imaging (radiology) procedures. According to the American College of Radiology, these tests include X-rays, computed tomography (CT), magnetic resonance imaging (MRI), nuclear medicine, positron emission tomography (PET), and ultrasound.
The older version barely misses the cut
Recently named the fastest growing consumer application ever, Dr. Bhayana says ChatGPT and similar chatbots are rapidly being integrated into popular search engines like Google and Bing — used by physicians and patients alike to search for medical information.
So, in order to analyze its performance on radiology board exam questions, as well as explore its strengths and limitations, Dr. Bhayana and a team tested ChatGPT based on GPT-3.5 (the most commonly used version). They designed and utilized a series of 150 multiple-choice questions to match the style, content, and difficulty of the Canadian Royal College and American Board of Radiology exams.
These questions did not include any images and researchers separated them according to inquiry type in order to gain further insight into performance. Those categories included lower-order (knowledge recall, basic understanding) and higher-order (apply, analyze, synthesize) thinking. Study authors also divided higher-order thinking questions even further according to type (description of imaging findings, clinical management, calculation and classification, disease associations).
They evaluated ChatGPT’s performance on an overall basis, as well as by question type and topic. Researchers also assessed the AI program’s confidence of language in its responses.
Ultimately, this led researchers to note that GPT-3.5 answered 69 percent of the questions correctly (104 of 150), which would be quite close to the passing grade of 70 percent used by the Royal College in Canada. The model also performed relatively well on questions requiring lower-order thinking (84%, 51 of 61), yet struggled with questions involving higher-order thinking (60%, 53 of 89).
More specifically, the chatbot had particular trouble with higher-order questions involving description of imaging findings (61%, 28 of 46), calculation and classification (25%, 2 of 8), and application of concepts (30%, 3 of 10). These poor performances did not surprise researchers due to the AI’s lack of radiology-specific pre-training.

ChatGPT-4 easily makes the grade
GPT-4, meanwhile, was released in March 2023 in limited form to paid users. This newest version claims to feature improved reasoning capabilities over GPT-3.5. So, researchers put together a follow-up study.
This time around, GPT-4 answered 81 percent of the same questions correctly (121 of 150), outperforming its older version and exceeding the passing threshold of 70 percent. GPT-4 also did much better than GPT-3.5 handling higher-order thinking questions (81%), especially queries involving the description of imaging findings (85%) and application of concepts (90%).
These findings strongly indicate that GPT-4’s claim of having advanced reasoning capabilities can indeed translate to enhanced performance within the context of radiology. This work also points to improved contextual understanding of radiology-specific terminology, including imaging descriptions, which will be critical to enabling future downstream applications.
“Our study demonstrates an impressive improvement in performance of ChatGPT in radiology over a short time period, highlighting the growing potential of large language models in this context,” Dr. Bhayana adds.
The program still suffers from ‘hallucinations’
GPT-4 did not show any improvements in reference to lower-order thinking questions (80% vs 84%) and also answered 12 questions incorrectly that GPT-3.5 answered correctly. Those results in particular raise questions in relation to its reliability for information gathering.
“We were initially surprised by ChatGPT’s accurate and confident answers to some challenging radiology questions, but then equally surprised by some very illogical and inaccurate assertions,” Dr. Bhayana explains. “Of course, given how these models work, the inaccurate responses should not be particularly surprising.”
Researchers note ChatGPT has a concerning and potentially dangerous tendency to produce inaccurate responses, called “hallucinations.” While these incidents occur less often with GPT-4, these deficiencies still limit the technology’s usability in medical education and practice, at least for now.
Both of these projects demonstrated that ChatGPT uses confident language consistently, even when it is incorrect. That is especially dangerous if the technology is solely relied on for information, Dr. Bhayana stresses, especially among medical novices who may not realize confident wrong answers are inaccurate.
“To me, this is its biggest limitation. At present, ChatGPT is best used to spark ideas, help start the medical writing process and in data summarization. If used for quick information recall, it always needs to be fact-checked,” Dr. Bhayana concludes.
The study is published in the journal Radiology.








“Both of these projects demonstrated that ChatGPT uses confident language consistently, even when it is incorrect.”, you mean just like real radiologists.
Humans (especially doctors and experts) are trained to respond confidently even (especially) when they don’t know the answers. They just make stuff up. (See Climate Change, Ozone Hole and Covid for examples.)